I've yapped about AI a couple times already, and it's pretty evident I was against having AI take the wheel. This time, however, it's a different kind of yap. The kind that is more concerning and more overlooked by many. The kind that if you were blindly giving in to AI, it should help open your eyes just a little.
What is Slopsquatting?
Slopsquatting is considered an evolution of the famous typosquatting attack. If you're not familiar with typosquatting, it's basically a classic form of malicious tampering, where an attacker relies on typos made in seemingly legitimate domains or URLs.
A good example of typosquatting is the famous "rnicrosoft.com" domains/emails. Because this page is written in a monospace font, you can clearly tell where the typo is - but this was a serious issue at some point.
Typosquatting was never that serious, at least not as serious as some other attacks and exploits, because of the fact it could be relatively easily spotted and mitigated.
Slopsquatting, however, is a more serious problem. A problem that can only exist in the agentic "vibe-coding" age.
The way it basically works is that an attacker would make use of an AI coding agent's hallucination and turn it into an actual malicious package. So, for example: You're working on a coding project, and you're vibe-coding your way through it and at some point the agent decides to install the dependency graphitorm which, in fact, is a package that does not really exist. (Currently, the package is reserved on PyPi as a research package for slopsquatting because of it being a common hallucination by agents.)
You probably know where this is going already... With enough information on the most hallucinated dependencies, an attacker can easily publish their own malicious packages - and with NPM and PyPI being two of the most frequent spots for AI agents and having a relatively easy way to deploy packages, this could get really ugly, really fast.
Why do hallucinations happen in the first place?
This boils down to the nature of those AI agents - the one that most people tend to forget. These Language Models are as good as the data they are trained on, and with their probabilistic nature, those types of hallucinations are actually more predictable than you'd imagine!
Large Language Models (LLMs), the things powering that agent you're running, are statistical models - meaning that they're just really good at making predictions, they do not really have any sort of "coherent" reasoning or thinking like we humans do. They don't have concrete knowledge, they're just always predicting whatever they "think" would fit best in the sentence they are spitting out.

The (sortof) good news
The authors of the paper on slopsquatting thankfully took the time to test this theoretical threat on real code.
They found out that mostly the ones that did hallucinate were mostly non-Frontier models. So if you're using a decent model, you are probably safe. This does not mean you should turn a blind eye to this. Hackers are always getting creative.
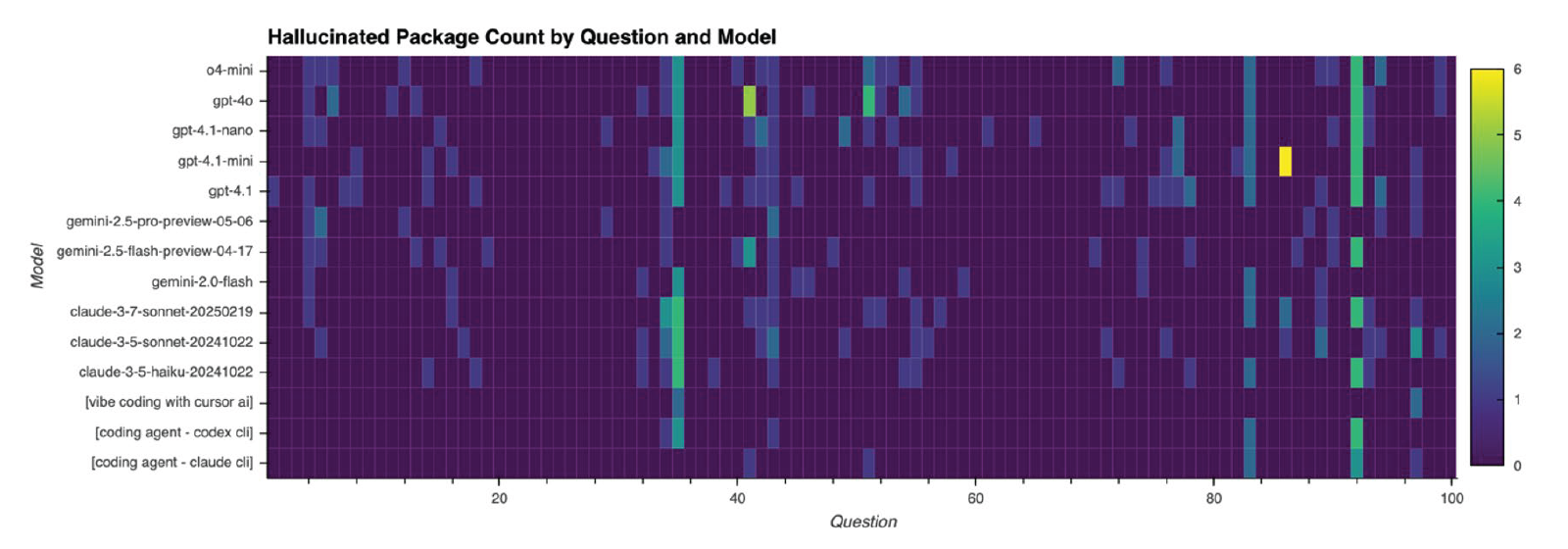
The paper also mentions that Coding Agents are less susceptible to this (by about 50%), but do not eliminate the threat completely either. For example, they could reproduce this on Cursor AI.
How to be safe
There are a few ways you could stay safe, I think the most effective one is just having some decent level of common sense enough to just know when your llm is about to screw up so you could just pull the brakes.
One other effective method is to run those agents in a sandboxed environment. Additionally, I think using MCPs like context7 could help reduce hallucinations significantly (but you can never really be sure.)
While this threat could sound like a long way from where we are, and it's all mostly theory... I do believe that it could shake up the industry fairly soon. I think this would also lead major package managers like NPM and PyPI to completely halt new package additions for a bit, or at least have those undergo a more rigorous form of checking. Hopefully not via AI.
References
If you'd like to read more about slopsquatting, give the post by the paper's authors a read: Slopsquatting: When AI Agents Hallucinate Malicious Packages
You can also find a more detailed analysis, specifically on hallucinations by models that were tested, through their github repository: https://github.com/trendmicro/slopsquatting